Reproduzierbare Analysen mit dem Open Source Statistikprogramm jamovi
Klausur Ausbildung und F+E (14.02.2023)
Jamovi
Jamovi ist ein Spreadsheet-Programm zur Durchführung von statistischenjam Analyse ähnlich zu SPSS
Vorteile: Open Source, kostenfrei, integrierte Dokumentation, modernes GUI, Integration mit R
Nachteile: “jung”, reduzierte Funktionalität (aber: Plugins, Integration mit R)
Installation: https://www.jamovi.org/user-manual.html#installation
Datensatz
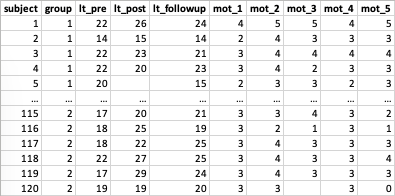
Simulierter Datensatz (N = 115)
subject
Beschreibung: eindeutige Identifikationsnummer der Teilnehmenden
Skala: Nominal (ID)
Ausprägung: 1 - 120
group
Beschreibung: Gruppe
Skala: Nominal
Ausprägungen: 1 == “Kontroll”, 2 == “Treatment”
Datensatz
lt_pre, lt_post, lt_followup
Beschreibung: (L)ern(T)test Prä, Post oder Follow-Up
Skala: Kontinuierlich
Ausprägungen: 0 - 30
mot_1 - mot_5
Beschreibung: Motivationskala Item 1 - 5
Skala: Kontinuierlich
Ausprägungen: 0 - 5
Dokumentation
Hinweise
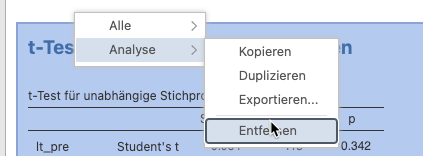
- Einzelne oder alle Analysen können über via Rechtsklick kopiert, exportiert und entfernt werden.
- Bestehende Titel können editiert werden.
Reproduzierbarkeit II
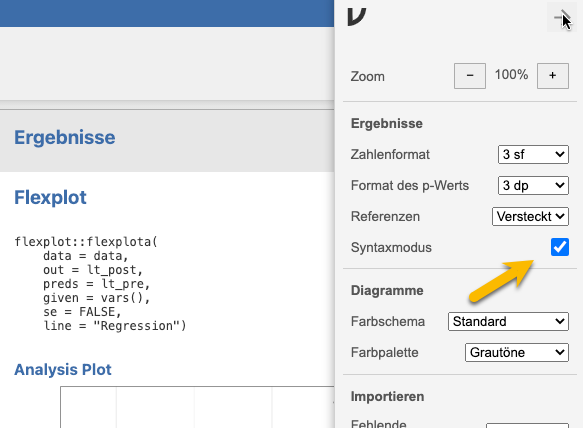
- R als Basis: “Syntaxmodus” zeigt Syntax, welche nach R kopiert und ausgeführt werden kann (auch ohne Jamovi-Oberfläche)